
Después de ver la teoría y aprender que es Kubernetes ahora vamos a ver los primeros pasos.
Los primeros son tareas comunes en Kubernetes (Instalar, ver la información, debugging y diferencias entre comandos). Luego ya entramos en como hacer cada objeto dentro de nuestro Clúster de Kubernetes.
Instalar Kubernetes
Este orquestador de contenedores se puede instalar en casi todos los sistemas operativos y procesadores virtualizables. Incluso en una Raspberry Pi puedes instalar Kubernetes.
Lo podemos seguir de la documentación oficial para instalar Kubernetes. También podemos instalar MiniKube que es indicado cuando solo tenemos un nodo.
Aunque lo normal es utilizar los proveedores Cloud para sacarle el máximo partido. Tenemos 300$ gratis durante 12 meses en Google Cloud. También tenemos 50€ en DigitalOcean al registrarse. Y en Azure tenemos 170€.
Ver la información básica
Ya tenemos el Clúster de Kubernetes instalado (o solo una máquina) y para comprobar que todo esta correcto (Ready) utilizamos:
kubectl cluster-info
kubectl get nodes
Con el comando get podemos ver también los pods o los cualquier otro objeto. El primer comando es para la estructura general del nodo maestro. El segundo es específicamente para el estado de los nodos.
Si hay algún fallo
Es típico que algún nodo no este listo (Ready) y de error (Not Ready). Como hay cientos de posibilidades vamos a analizar en especifico que pasa. Es lo que se conoce como Debugging, en español Depuración de programa. Lo primero es ver el estado de los nodos:
kubectl get nodes
Y ahora vamos a ver un poco más sobre ellos. Después de este comando podemos poner el nombre del nodo solo para ver la información de él o dejarlo así y ver la de todos:
kubectl describe nodes
Buscamos donde pone Events y ahí podemos ver el tipo, si es un error (Warning), la razón y el mensaje.
El proceso es el mismo para los pods. Solo que cambiamos en los anteriores comandos nodes por pods. Ademas podemos utilizar el siguiente comando para ver los eventos específicos del interior de los contenedores del pod.
kubectl logs (nombre-del-pod)
A su vez, también podemos ver los deployments. Al igual que antes utilizamos get y describe:
kubectl get deployments
kubectl describe deployment
Diferencia entre apply y create
La diferencia entre kubectl apply -f archivo.yaml y kubectl create -f archivo.yaml es muy sutil. Ambos puedes crear los objetos pero con el apply puedes modificar después el archivo YAML.
Después de un apply puedes hacer otro apply para cambiar la configuración existente. Si hacemos un create tenemos que borrarlo primero y volver a crearlo (aunque puedes sobreescribirlo con replace).
Básico en cualquier objeto
Dentro del archivo YAML para crear cualquier objeto tenemos que escribir (o hacer un CTRL+C y CTRL+V de toda la vida) varias especificaciones. Si olvidamos o necesitamos voler a ver cualquiera podemos usar el comando explain. Este comando se puede aplicar directamente al objeto o a una epecificacion tanto general como especifica.
kubectl explain pod
kubectl explain pod.apiVersion
Ademas nos da el enlace directo hacia cada departamento de la documentación oficial.
- apiVersion:
Podemos modificar la API e incluso usar una propia. Pero lo más normal es usar la v1 o v1beta1.
- kind:
Podemos representar cualquier Objeto: Pod, ReplicaSet, Service, Namespace, Node.
- metadata:
Dentro de metadata debe incluir obligatoriamente:
-
- name:
- El nombre de este objeto Pod.
- namespace:
- En realidad este lo podemos dejar sin rellenar y va a utilizar por defecto (default) como NameSpace.
- uid:
- Al igual que namespace, podemos no ponerlo manual. Si no lo ponemos en el archivo YAML creará su propio identificador. Lo habitual es no poner ni el namespace (a menos que quieras especificar uno en concreto) ni el uid.
Y dentro de metadata puede tener opcionalmente:
-
- labels:
- Son necesarias para organizar o luego utilizar otros objetos conjuntamente. Se pueden poner tantas etiquetas como queramos.
- spec:
Básicamente son las especificaciones de cada contenedor del Pod/ReplicaSet/Deploy. Es muy configurable así que solo vamos a ver lo básico ahora:
-
- containers:
- Indica, en formato array (que podemos añadir tantos como queramos con el símbolo -), que va crear 1 contenedor o varios. Dentro podemos indicar las características de dicho contenedor específico.
-
- image:
- La ruta de la imagen para el contendor. Podemos utilizar las de Docker Hub, tanto del repositorio oficial o de uno privado, también imágenes locales. Se pueden usar tags. Igual que en Docker.
- name:
- El nombre de cada contenedor. Puede ser el mismo que el de la imagen o personalizarlo.
- initContainers:
-
- Son también contenedores pero que se ejecutan solo durante el inicio del Pod. Se suele usar la imagen del busybox para hacer tareas por su bajo peso. Tiene las mismas características que un contenedor normal.
Filtrado de labels (etiquetas) con Selectors
Bueno más adelante vamos a ver otros usos de las etiquetas pero el del filtrado también es muy importante cuando nuestro Clúster crece. El filtrado lo hacemos a los objetos que queramos utilizando -l o –selector=’ ‘
kubectl get pod -l tipo=proyectoweb
kubectl get pod --selector='tipo=proyectoweb'
Admite el filtrado de varias etiquetas (añades más con comas) y los operadores binarios =, == y !=
kubectl get pod -l tipo!=proyectoweb,rama=desarrollo
Creación del primer Pod
Como ya hemos visto lo que es un Pod en la teoría, vamos a crear uno. Lo normal es que dentro de un Pod haya solo un contenedor (aunque puede haber más si necesitas, por ejemplo, compartir volúmenes entre ellos o van a interactuar directamente sin necesidad de especificar la IP de cada uno).
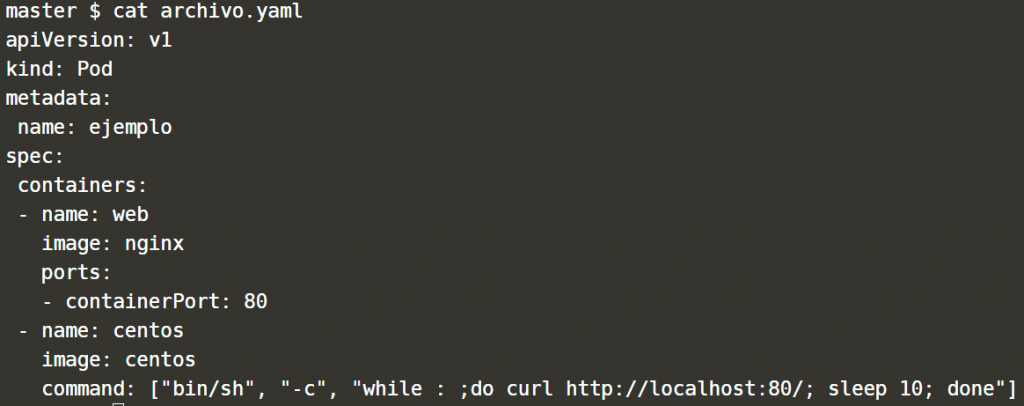
Ejemplo YAML de un Pod
Recordamos que el lenguaje YAML tiene 2 normas importante. Hay que respetar los espacios (no recomendado usar tabulaciones) y hay que respetar las mayúsculas. También recordamos que el – en YAML significa un array, por lo que podemos añadir tantos (por ejemplo contenedores) como queramos tan solo añadiendo más.
En este ejemplo vamos a crear 2 contenedores en un mismo Pod, con Nginx (servidor web) y CentOS (un sistema operativo).
apiVersion: v1 kind: Pod metadata: name: ejemplo spec: containers: - name: web image: nginx ports: - containerPort: 80 - name: centos image: centos command: ["bin/sh", "-c", "while : ;do curl http://localhost:80/; sleep 10; done"]
Como nota, containerPort es meramente informativo, si no lo pusiéramos los contenedores al estar en un mismo Pod se exponen automáticamente (gracias a ClusterIP).
kubectl create -f archivo.yaml
En el siguiente comando podemos añadir -o wide para ver más información. Si lo ejecutamos al segundo vemos como están creándose (ContainerCreating).
kubectl get pods
Podemos ver si ha sido todo correcto con logs. Con el -c vamos a ver concretamente el contenedor centos para ver el resultado del curl. Si no te acuerdas puedes ver rápidamente el nombre de los contenedores si no pones -c centos.
kubectl logs ejemplo -c centos
Y por último para borrar el contenedor.
kubectl delete pod ejemplo
Creación del primer ReplicaSet
Elimina las caídas de los nodos gracias a la replicación de estos. Como hemos visto en la teoría utiliza las etiquetas (labels) para saber que pods tiene que replicar. Puede crear sus propios pods con template.
Lo único que cambia de la estructura del pod es la primera parte a la hora de crear el ReplicaSet. El kind (tipo) ahora es ReplicaSet y dentro del spec del ReplicSet tenemos 2 nuevas especificaciones que se llaman:
- replicas: Indicamos el número de contenedores totales que queremos tener simultáneamente.
- selector:
Ejemplo YAML de un ReplicaSet
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: ejemplo2
spec:
replicas: 3
selector:
matchLabels:
proyecto: ejemplo
template:
metadata:
name: nginx
labels:
proyecto: ejemplo
utilidad: web
cualquier: otracosa
spec:
containers:
- name: web
image: nginx
ports:
- containerPort: 80
Pruebas que podemos hacer para comprobar que funciona: Podemos borrar un Pod y ver como lo crea al instante. Podemos borrar el ReplicaSet, crear un Pod con las etiquetas (labels) y luego crear el ReplicaSet y así vemos como utiliza el Pod ya creado y hace solo 2 (en mi caso de ejemplo) replicas. Podemos
Recuerda que las etiquetas pueden ser totalmente personalizadas. Y si quieres poner números utiliza las comillas.
Creación del primer Deployment
Tal y como vimos en la teoría, el Deployment es el siguiente nivel. Controla tanto Pods como ReplicaSet. Y añade la funcionalidad de la liberación continua (rolling updates) con lo que en vez de sustituir todo el programa, sustituye solo la parte actualizada. También añade la vuelta atrás (roll back).
Ejemplo YAML de un Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: ejemplo3
labels:
proyecto: ejemplo3
spec:
replicas: 3
selector:
matchLabels:
proyecto: ejemplo3
template:
metadata:
labels:
proyecto: ejemplo3
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Ahora ya podemos ver con un kubectl get tanto los Pods como el ReplicaSet.
Services
Recuerda de la teoría que los Pods son efímeros. Por lo tanto sus IPs también. Si un Pod se cae y se levanta otro, su IP puede cambiar y si lo tenemos conectado con otra aplicación esta dejará de funcionar.
Para que esto no pase utilizamos los Services. Vamos a volver a ver los tipos pero en práctica. Las IPs de las imágenes son simplemente ilustrativas, según cada configuración del clúster.
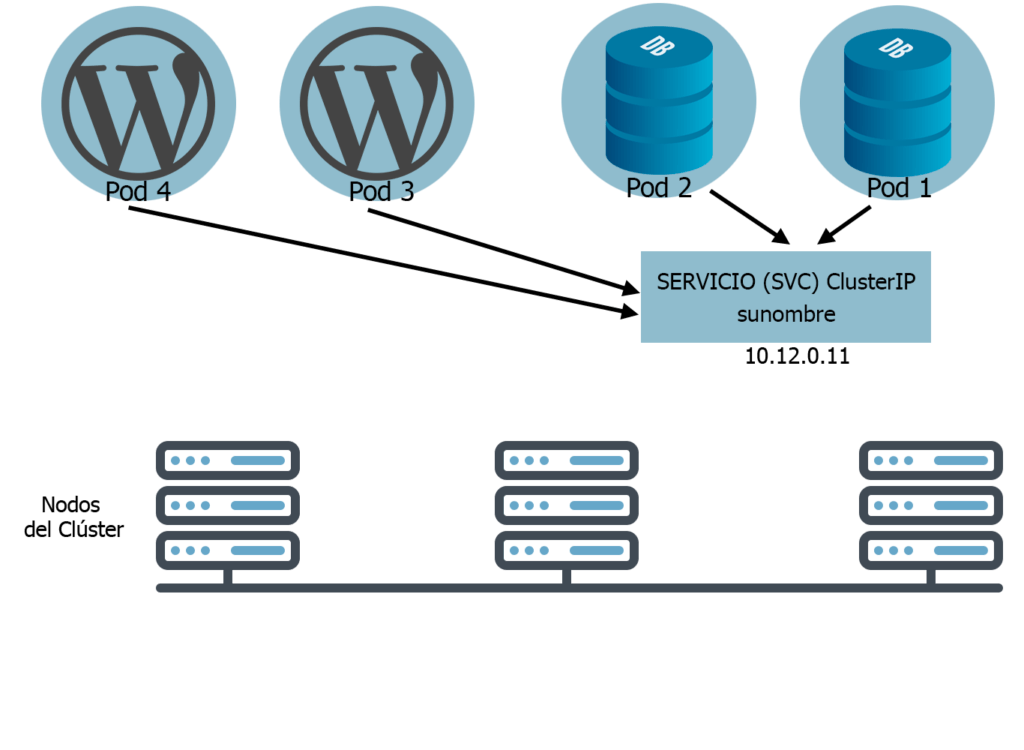
ClusterIP
Interno. Comunicación entre varios pods, ReplicaSet, Deployments. En vez de tener que configurar cada comunicación hacia cada IP simplemente usamos un Service ClusterIP que nos va a dar una IP “fija” por decirlo así.
En el ejemplo de abajo vemos como hay varios Pods de diferentes aplicaciones. Queremos agrupar los de tipo base datos bajo una misma IP para que los de tipo WordPress se comuniquen solo a esa IP.
Dentro del servicio podemos configurar la redirección de los puertos que queramos.
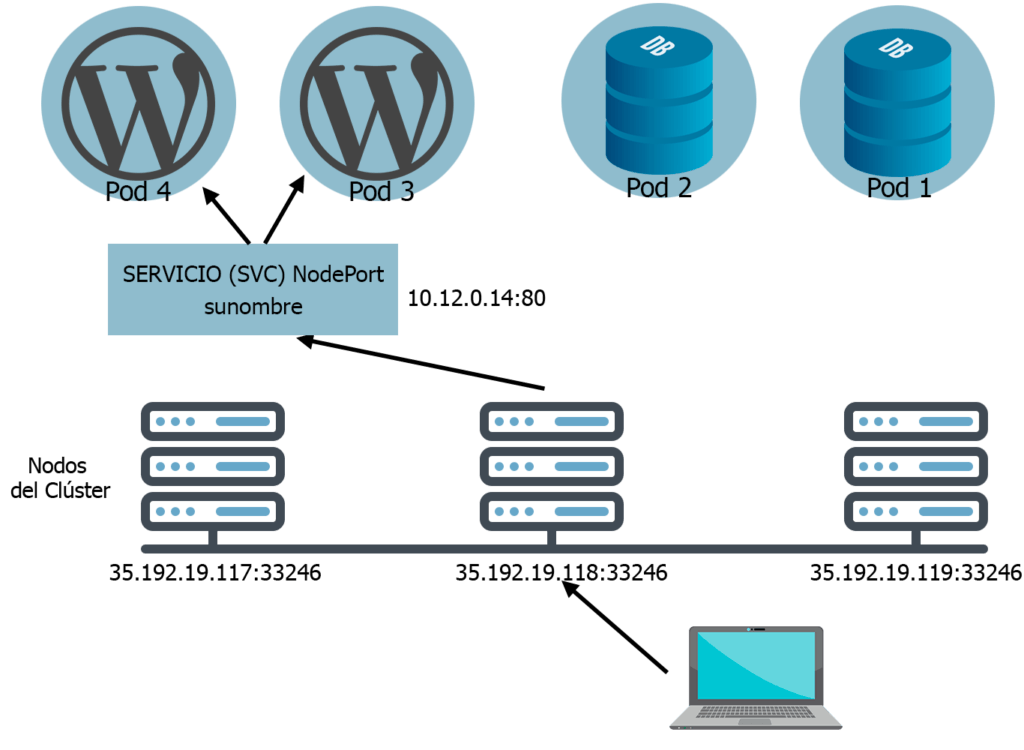
NodePort
Ya no es solo interno. Ahora podemos acceder a una aplicación desde el exterior. Solo tenemos que conectarnos a la IP de cualquier nodo y al puerto que le haya asignado por defecto el servicio.
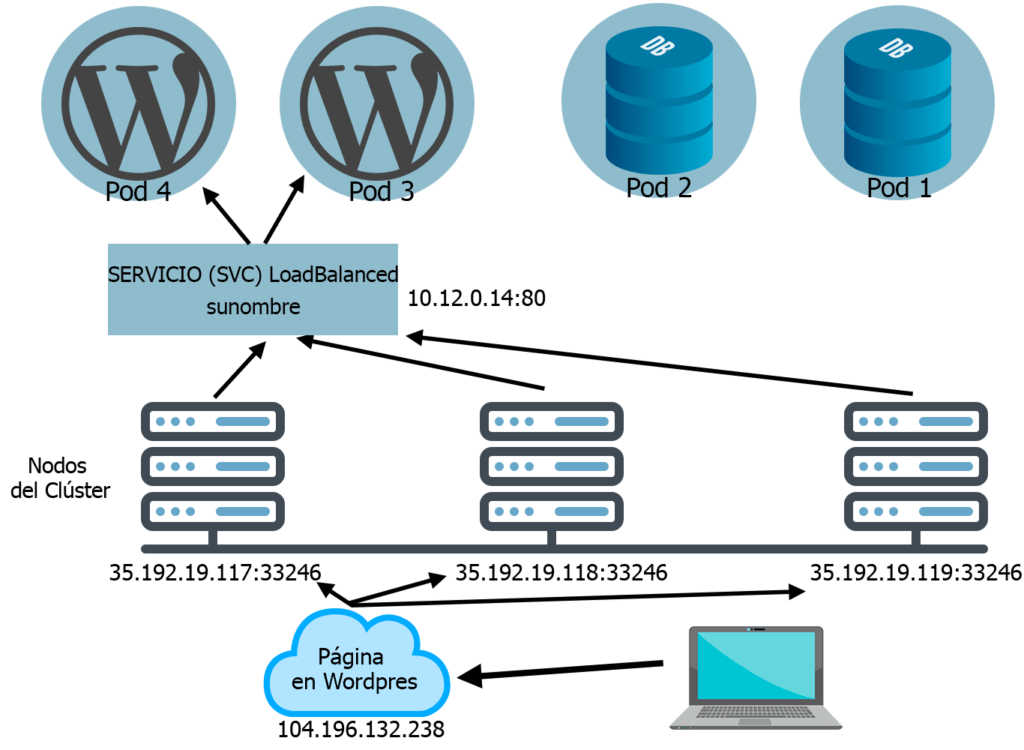
LoadBalancer
Le suma un paso más al Service NodePort. Se suele decir que solo se puede hacer en empresas Cloud ya que en local es difícil tener las medios para que la carga este realmente balanceada.
Como decíamos, le suma un paso más al anterior Service. Con el Service LoadBalancer puedes acceder a la aplicación de forma externa pero sin necesidad de recordar el puerto asignado por defecto de cada nodo.
Hay una excepción que puedes crear un Ingress-Controller para gestionar varios LoadBalancer. Pero eso lo veremos más adelante. Ahora vamos a ver como crear los 3 tipos de Services.
Ejemplo YAML de un Service ClusterIP
Primero crear el Service (el orden en realidad no importa):
apiVersion: v1
kind: Service
metadata:
name: nuestro-servicio-para-nginx-cip
spec:
selector:
proyecto: ejemplo3
utilidad: web
ports:
- protocol: TCP
port: 80
targetPort: 80
name: http
Como podemos ver no especificamos ningún tipo (type) ya que ClusterIP es la opción por defecto. Ahora vamos a crear un ReplicaSet, aunque podía ser un simple Pod o un Deployment, con las mismas etiquetas (labels) para que lo utilice:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
spec:
replicas: 2
selector:
matchLabels:
proyecto: ejemplo3
utilidad: web
version: "0.1"
template:
metadata:
name: nginx
labels:
proyecto: ejemplo3
utilidad: web
version: "0.1"
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Ahora ya podríamos ver la IP interna asignada con kubectl get service y para ver también más datos, como los EndPoints (por decirlo así, son como la IP de cada Pod pero asignada por la API) utilizamos:
kubectl describe service nuestro-servicio-para-nginx
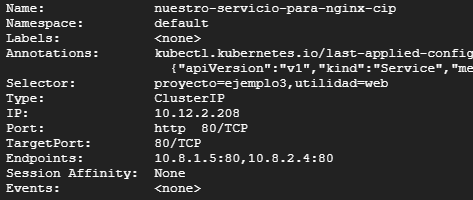
Con ambos comandos vamos a poder ver la IP interna. Kubernetes guarda esa IP en una variable de entorno así que podemos utilizar esta variable o utilizar directamente la IP.
| ${NOMBRE DEL SERVICIO}_SERVICE_HOST | |
| ${NOMBRE DEL SERVICIO}_SERVICE_PORT | |
| ${NOMBRE DEL SERVICIO}_PORT | |
| ${NOMBRE DEL SERVICIO}_PORT_${PUERTO}_${PROTOCOLO} | |
| ${NOMBRE DEL SERVICIO}_PORT_${PUERTO}_${PROTOCOLO}_PROTO | |
| ${NOMBRE DEL SERVICIO}_PORT_${PUERTO}_${PROTOCOLO}_PORT | |
| ${NOMBRE DEL SERVICIO}_PORT_${PUERTO}_${PROTOCOLO}_ADDR |
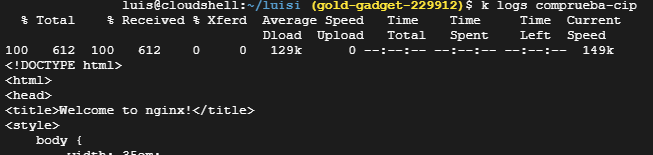
Para hacer la comprobación y utilizar ya de paso las variables podemos hacer un Pod rápido y luego ver con
logs:
apiVersion: v1
kind: Pod
metadata:
name: comprueba-cip
spec:
containers:
- name: centos
image: centos
command: ["/bin/sh", "-c", "while : ;do curl http://${NUESTRO_SERVICIO_PARA_NGINX_CIP_SERVICE_HOST}:80/; sleep 10; done"]
Recuerda las variables aunque las tienes que declarar con barra bajas (_) siempre. En nuestro ejemplo el Service se llama nuestro-servicio-para-nginx-cip pero la variable va a pasar a llamarse NUESTRO_SERVICIO_PARA_NGINX_CIP a parte de lo que queramos indicar. En el ejemplo solo el host.
Ejemplo YAML de un Service NodePort
Primero vamos a borrar solo el anterior servicio ClusterIP nuestro-servicio-para-nginx-cip y vamos a reutilizar el mismo ejemplo de ReplicaSet, así que no hace falta borrarlo, solo asignamos los selector con las mismas labels.
kind: Service
apiVersion: v1
metadata:
name: nginx-nodeport
spec:
type: NodePort
selector:
proyecto: ejemplo3
utilidad: web
ports:
- protocol: TCP
port: 80
targetPort: 80
Ya podrías acceder con el puerto y el nodo. Para ver el puerto utilizamos:
kubectl get services
Y para ver la IP externa de los nodos utilizamos:
kubectl get nodes -o wide
http://IP DEL NODO:PUERTO ASIGNADO POR EL SERVICIO
Como podemos ver en el YAML lo que cambiaría sería que ahora ya tenemos que especificar el tipo (type) de Service que es.
Ejemplo YAML de un Service LoadBalancer
Como decíamos, este tipo es especifico en Cloud (Azure, AWS, Google, etc).
kind: Service
apiVersion: v1
metadata:
name: nginx-loadbalancer
spec:
type: LoadBalancer
selector:
proyecto: ejemplo3
utilidad: web
ports:
- protocol: TCP
port: 80
targetPort: 80
Una vez creado ya solo tenemos que ejecutar un comando para ver la IP externa puesta por el proveedor Cloud. Esperamos un poco mientras lo crea pondrá en External IP <pending>.
kubectl get services
Y accediendo a esa IP ya podemos ver nuestra aplicación web sin necesitad de puertos.

Un consejo es qué en vez de poner todo el rato kubectl se puede poner tan solo k y ya lo interpreta(o sino usar un alias clásico de Linux: alias k=kubectl). Esto ahorra mucho tiempo. También hay otros como en vez de Pod poner po, en vez de ReplicaSet poner rs y en vez de service poner svc. Podemos utilizar tanto el plural como el singular para los objetos (daría igual Pod que Pods).
Más información: https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.10
[yasr_overall_rating]
