
Ya hemos visto toda la teoría de Kubernetes y en los primeros pasos como crear los objetos básicos en Kubernetes, ahora vamos a ver un par de objetos más avanzados.
Resumen del artículo
Secret y ConfigMap
Las aplicaciones suelen necesitar archivos de configuración. Y para pasarlos están los Secrect y los ConfigMap. Son 2 objetos DISTINTOS pero muy similares, la diferencia radica en que los Secrets la información va cifrada y el ConfigMap no. Por eso los Secrets se utiliza para información más sensible y los ConfigMap para información más simple.
Ambos objetos se pueden utilizad de dos maneras. Directamente pasando el archivo de configuración o pasando variables de entorno.
Luego hay varios tipos de Secrets pero en su mayoría son del sistema de Kubernetes, el que vamos a utilizar es type: Opaque que ademas es el Secret por defecto (así que podemos quitar el type).
Luego hay un tipo de Secret que aunque no sea el habitual si es útil. Es el docker-registry y como su nombre indica es para el registro de docker, donde se guardan las imágenes.
Creación de un Secret
Para este tipo de objeto, a diferencia del resto, es mejor utilizar directamente la terminal. Aunque también se podrían hacer de forma clásica con un archivo YAML.
Como habíamos dicho, podemos utilizar los Secret (también los ConfigMap), de 2 maneras.
Creación de un Secret archivo
Se pueden pasar tantos archivos como queramos dentro de un Secret. Esto es muy utilizado para archivos de configuración amplios que tengan datos sensibles como contraseñas o usuarios administradores. Recordamos que generic es igual a Opaque.
kubectl create secret generic nombre-de-nuestro-secret --from-file=UnArchivo.txt --from-file=/directorio/OtroArchivo.zip
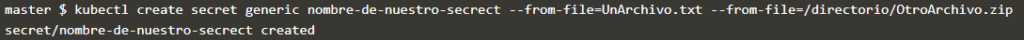
Una variedad de este método muy interesante es decirle que coja todos los archivos de un directorio. Hace lo mismo que ir indicandolo uno a uno. El procedimiento es el mismo, con la terminal, pero en vez indicar la ruta de cada archivo indicamos la ruta del directorio que los contiene: --from-file=/directorio
También hay otra variedad que se basa en utilizar --from-literal=nombrearchivo=contenido. Crea el archivo con el contenido.
Utilizar el Secret archivo
Para este primer método necesitamos añadir un volumen al Pod (o cualquier otro objeto) para almacenar y utilizar los archivos contenidos en el Secret. Simplemente vamos a utilizar como base el Objeto Pod que ya aprendimos a hacer en los primeros pasos (vamos a quitar el otro contenedor de CentOS ya que no necesitamos comprobar eso).
apiVersion: v1 kind: Pod metadata: name: ejemplo spec: containers: - name: web image: nginx ports: - containerPort: 80 volumeMounts: - name: nombre-volumen mountPath: /directorio/dentro readOnly: true volumes: - name: nombre-volumen secret: secretName: nombre-de-nuestro-secret
En el ejemplo anterior añadimos el volumen dentro del array del contenedor. Con volumeMounts. Como podemos ver, también es un array y por lo tanto podríamos añadir más. El nombre (name) es importante, ya que tiene que ser el mismo que en el siguiente paso. El punto de montaje (mounthPath) es la ruta en la que van a estar los archivos. El readOnly es opcional e indica los permisos sobre el directorio.
El siguiente añadido que podemos ver es el volumes. Este esta en el nivel del contenedor (containers). Y también tiene formato array. Es importante que el nombre (name) coincida con el del paso anterior. Como todos los volúmenes tenemos que especificar el tipo, en este caso secret. Y en este subnivel especificamos el nombre del secret que creamos previamente con secretName.
Podemos especificar también el path (la ruta) de un archivo en cuestión o de cada uno. Más información en la documentación.
Creación de un Secret variables de sistema
La otra manera en la que podemos pasar información sensible es en formato de variables de sistema. No necesitas añadir ningún volumen ya que la propia naturaleza de las variables de sistema es que estén, en todo el sistema.
Este método suele ser usado cuando necesitamos contraseñas o credenciales sin archivos.
En realidad la creación de un Secret de variables de sistema es igual que uno de archivos.
kubectl create secret generic nombre-de-nuestro-secret --from-literal=USUARIO=luis
Utilizar el Secret variables de sistema
Lo que si cambia es en el archivo de cada objeto. Ya no necesitamos volúmenes pero ahora necesitamos especificar las variables.
apiVersion: v1
kind: Pod
metadata:
name: ejemplo
spec:
containers:
- name: web
image: nginx
ports:
- containerPort: 80
env:
- name: SECRET_USUARIO
valueFrom:
secretKeyRef:
name: nombre-de-nuestro-secret
key: USUARIO
Ahora si accedemos a nuestro Pod podremos ver que hay una variable del sistema llamada SECRET_USUARIO y su valor es el mismo que le hemos puesto en el Secret a USUARIO.
Para verla podemos entrar en el Pod y ejecutar el comando echo $SECRET_USUARIO. Para entrar lo vamos a ver a continuación.
Conectarse a un Objeto (ejecutar comandos)
Aunque no es avanzado, no lo hemos visto en Kubernetes. Es muy simple. Vamos a ver como abrir una shell en un Pod, por ejemplo.
kubectl exec -it nombre-del-Pod -- /bin/bash
Recuerda que puedes ejecutar cualquier comando, no necesitas abrir la terminal para ello. Solo cambias el — /bin/bash por el comando.
kubectl exec -it nombre-del-Pod ls /
Pero también puede que dentro de un Pod (por decir un objeto) tengas más de un contenedor. Entonces añadimos el parámetro --container o en versión corta -c especificando en nombre del contenedor que va a ejecutar el comando.
kubectl exec -it nombre-del-Pod --container mysql ls /
Recuerda que puedes ver todos los comandos con kubectl --help.
Almacenar datos en volúmenes
El volumen guarda datos de otros objetos (por ejemplo de los Pods). Tiene bastante similitudes con los volúmenes tradicionales (discos duros de toda la vida, sin particionar eso sí).
Tiene 2 tipos base que a su vez se dividen. El primer tipo de volumen es el “efímero“, el emptyDir. El segundo tipo es el persistente, hay como 20 posibles, por ejemplo, cada Cloud tiene su propio tipo de almacenaje (Google Cloud usa los gcePersistentDisk) y luego podemos usar varios sistemas de archivos externos.
Primer tipo de Volúmenes: “Efímeros”
Yo los llamo efímeros porque tienen una característica clave. Si se cae el Pod, se pierden los datos. ¿Entonces que sentido tienen, no puedo guardar nada?. Sí y no. Este tipo de volúmenes se utilizan para compartir archivos entre los contenedores de cada Pod.
Son directorios temporales. Y si se cae un contenedor, no se pierde. Se tiene que caer el Pod para que se perdiera.
Un ejemplo claro de utilización es si tenemos un Pod que tiene un contenedor con un servidor web y otro con una herramienta de análisis de errores. Entonces para compartir los registros del servidor web (logs) y qué los analicé la herramienta se utiliza ese volumen temporal. Luego podemos añadir el siguiente tipo de discos para preservar los análisis que es lo que más nos interesa.
No necesitan crear un objeto especifico para utilizarlos.
Son, por ejemplo:
- emptyDir
- gitRepo (En desuso, obsoleta)
- downwardAPI (muestra información sobre el Pod)
- hostPath (No útil en Cloud o varios nodos, además no es efímero teoricamente, los datos se guardan en 1 nodo, aunque los nodos pueden borrarse)

Segundo tipo de Volúmenes: Persistentes
Los temporales nos ahorran muchos recursos, pero necesitamos tener nuestros datos bien guardados. Para ellos está este segundo tipo.
Este tipo de volúmenes necesitan una configuración previa. Con que requieren una configuración previa me refiero a que:
- Si estamos en un Cloud ( ya sea Google, AWS, Azure, etc) tenemos que crear el disco antes de poder añadir el volumen al Pod. En realidad es normal, no tiene sentido querer añadir un disco sin tenerlo físicamente por decirlo así. Por ejemplo en el Cloud de Google podemos crear el disco mediante la terminal (
gcloud compute disks create --size=200GB --zone=us-central1-a nombre-disco) o buscando en el menú: Compute Engine ➝ Discos. Cada Cloud tiene su forma de crearlos que puedes encontrar en su información. - Si tenemos nuestro propio sistema de archivos distribuido. Pues necesitamos configurar ese sistema de archivos. Kubernetes tiene mucha compatibilidad y soporta muchos tipos diferentes. Los más utilizados son NFS y CephFS. También tiene novedades como StorageOS.
- Además permite utilizar canales de fibra óptica (fiber channel) e iSCSI. Este tipo se suele usar en grandes centros de datos o supercomputadores.
Utilizar volúmenes para almacenar datos
Ya hemos visto los dos tipos de volúmenes y sus características. Su creación es prácticamente igual (quitando que el segundo tipo tenemos que hacer el paso previo de crear el disco y añadir sus características especificas).
Utilizamos el ejemplo de siempre de creación de un Pod simple.
En ambos tipos de almacenamiento (Efímeros o Persistentes) vamos a especificar 2 cosas en el YAML del Pod. La primera es debajo del nivel del contenedor, en el array de cada uno de ellos vamos a especificar volumeMounts: que a su vez, va a tener la ruta del punto de montaje dentro del contenedor (mountPath) y el nombre del volumen (name).
Luego, fuera del contenedor, a su mismo nivel. Vamos a añadir el volumen. Tiene formato array así que al igual que con el punto de montaje volumeMounts: podemos añadir más de uno. Tiene su nombre, que debe ser el mismo. Y luego el tipo de disco. En el tipo de disco tenemos que saber varias características propias de cada uno que tenemos que añadir.
Nota: EmptyDir es el único que no lleva características y va seguido de dos llaves cerradas {}.
apiVersion: v1
kind: Pod
metadata:
name: ejemplo
spec:
containers:
- name: web
image: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /directorio
name: mi-volumen
volumes:
- name: mi-volumen
emptyDir: {}
Para ver otro ejemplo vamos a utilizar el segundo tipo de volúmenes: Persistentes. Y en específico el en Google Cloud. Para ello vamos a crear el disco como dije anteriormente, tanto por la terminal o en la página. Y vamos a crear el archivo YAML de un Pod. Puedes ver entre los dos ejemplos que no cambia nada. Solo que añadimos en volumes: las especificaciones propias de los discos de Google gcePersistentDisk. Qué recordamos, que podemos buscar en la página de volumes de kubernetes.
apiVersion: v1
kind: Pod
metadata:
name: ejemplo
spec:
containers:
- name: web
image: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /directorio
name: mi-volumen
volumes:
- name: mi-volumen
gcePersistentDisk:
pdName: nombre-disco
fsType: ext4
Como podemos ver, el nombre del volumen (tiene que coincidir en volumeMounts: y en volumes:) no tiene que ser el mismo del nombre del disco físico creado.
Abstracción del almacenamiento
Ya sabremos crear volúmenes y tener almacenamiento en Kubernetes. Pero ese es el caso que tu mismo seas el administrador del Cloud. Lo normal es que este dividido en:
- Los desarrolladores son los que utilizan el Cloud
- Los técnicos son los que administran el Cloud
Un desarrollador no tiene por que saber ni siquiera en que Cloud está y por lo tanto no tiene que saber los tipos de discos ni sus características. Para ello Kubernetes nos da la posibilidad de crear una capa de abstracción más. Sí, como vimos en la teoría básica con la metáfora: Un Pod es como una capa opaca, interactúas directamente con el pod y él se encarga de los contenedores, en ningún momento ves los contenedores.
El Objeto Persistent Volume (PV)
Ahora vamos a crear esa capa opaca pero para los discos. Para ello está el objeto: Persistent Volume (PV). Este tipo de objeto tiene una unión 1 a 1. Lo que quiere decir que cada disco solo se puede unir a un PV. Y en el tenemos que especificar los datos técnicos del disco con el que se va a unir.
Vamos a tener que especificar el nombre (name), la capacidad (storage), el método de acceso (accessModes) y la política de uso (persistentVolumeReclaimPolicy). Las dos primeras son al gusto.
Podemos indicar el tipo de uso que va a utilizar cada disco. Dentro de los modos de acceso tenemos 3 opciones:
- ReadWriteOnce: El volumen va a poder ser utilizado por 1 objeto como lectura y escritura.
- ReadOnlyMany: El volumen va a poder ser utilizado por varios objeto en solo lectura.
- ReadWriteMany: El volumen va a poder ser utilizado por varios objeto como lectura y escritura.
En la política de uso vamos a especificar lo que va a pasar con cada volumen cuando se borre el Persistent Volumen Claim (PVC) asociado a este, lo vamos a ver a continuación lo que es un PVC. También tenemos 3 opciones:
- Retain: El disco asociado se va a la papelera y podemos elegir borrarlo o recuperarlo.
- Recycle: Lo que haya en el volumen se borra (rm -rf /volumen/*) y se puede volver a asignar.
- Delete: El disco asociado se borra.
Ademas, podemos utilizar un método de creación de volúmenes automáticos, así evitar tener que crear de forma manual (estática) los volúmenes y que se hagan automáticos (dinámica). Pero eso lo veremos más adelante. Seguimos con los PVC.
El Objeto Persistent Volumen Claim (PVC)
Luego vamos a ver las dos partes prácticas de como crear un PV y un PVC juntas. Imaginemos que ya tenemos un disco creado, por ejemplo en Google Cloud, lo hemos unido a el objeto Persistent Volumen para abstraerlo. Pero aún tenemos que hacer solo 2 pasos más.
El primer paso es crear el objeto Persistent Volumen Claim (PVC). Este objeto va a tener las características resumidas de 1 Persistent Volume (PV). Y va a tener la relación 1 a 1.
El último paso es unirlo a un Pod (Deployment, ReplicaSet, etc). Es mucho más fácil de lo que podemos imaginar, ya que es exactamente igual que cuando montamos el disco directamente del Cloud. Pero especificando el nombre del Objeto Persistent Volume (PV) en el apartado de volumes del Pod.

Crear el Objeto Persistent Volume (PV)
Tan solo tenemos que crear el archivo YAML. Indicamos la capacidad (storage), el método de acceso (accessModes) y la política de uso (persistentVolumeReclaimPolicy). Podemos indicar más características avanzadas.
apiVersion: v1
kind: PersistentVolume
metadata:
name: cualquier-nombre-del-persistent-volume
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Delete
gcePersistentDisk:
pdName: nombre-del-disco
fsType: ext4
Crear el Objeto Persistent Volumen Claim (PVC)
Y para crear el Persistent Volumen Claim (PVC) igual, con un objeto YAML. Esta vez especificamos también el método de acceso (accessModes) y la capacidad mínima. Eso significa que va a buscar un disco que como mínimo tenga 8 Gi, por ejemplo va a utilizar el PV anterior que tiene un disco de 50 Gi.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cualquier-nombre-del-persistent-volume-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
selector:
matchLabels:
release: "stable"
Ademas podemos utilizar selectors (como vimos en los primeros pasos con kubernetes) para indicar el tipo de PV que queremos usar. Por ejemplo si hemos utilizado labels para distinguir los discos SSD de los HDD.
Un ejemplo de un Pod con un PV y PVC
Reutilizamos el Pod de ejemplo del articulo sobre los primeros pasos en Kubernetes. Y también reutilizamos los ejemplos de los PV y PVC, tan solo tenemos que crear un disco y especificarlo en el PV.
apiVersion: v1
kind: Pod
metadata:
name: ejemplo
spec:
containers:
- name: web
image: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /directorio
name: mi-volumen
volumes:
- name: mi-volumen
persistentVolumeClaim:
claimName: cualquier-nombre-del-persistent-volume-claim
Automatizar los PV con StorageClass
También podemos automatizar los PV con un objeto llamado: StorageClass. Para crearlo como todos los objetos en un YAML:
kind: StorageClass apiVersion: storage.k8s.io/v1beta1 metadata: name: el-nombre-que-queramos provisioner: kubernetes.io/gce-pd parameters: type: pd-standard
En este ejemplo estamos en el Google Cloud (GKE), si fuera otro tenemos que cambiar el provisioner. Y en este Cloud podemos elegir entre los discos HDD o SDD. Este ejemplo son discos HDD, si queremos SDD cambiamos pd-standard por pd-sdd.
Ahora en nuestro PVC solo tenemos que hacer un cambio. Añadimos en metadata una anotación. El mismo ejemplo anterior pero con la anotación:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cualquier-nombre-del-persistent-volume-claim
annotations:
volume.beta.kubernetes.io/storage-class: el-nombre-que-queramos
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
selector:
matchLabels:
release: "stable"
Diferencia entre Deployment y StatefulSets
Es una pequeña diferencia pero muy importante. Los Deployment tratan todos sus Pods como 1. Y los StatefulSets les dan individualidad con identificadores y almacenamiento indivividual.
Así que si quieres crear replicas y que cada una tenga su disco tienes que usar StatefulSets.
Ejemplo StatefulSets
Vamos a ver un ejemplo de este Objeto y como aplicar también los StorageClass. Para ello vamos a crear el mismo ejemplo de StorageClass que hicimos antes. Una vez lo tengamos listo ya solo queda crear el StatefulSets.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: ejemplo
spec:
selector:
matchLabels:
app: nginx # Etiqueta para los Pods
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx # Etiqueta para los Pods
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: mi-volumen
mountPath: /directorio
volumeClaimTemplates:
- metadata:
name: mi-volumen
annotations:
volume.beta.kubernetes.io/storage-class: el-nombre-que-queramos
spec:
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
resources:
requests:
storage: 5Gi
Como podemos ver, dentro de volumeClaimTemplates podemos poner lo mismo que poníamos en los PVC.
Unir varios objetos en un mismo archivo YAML
Aunque esto tampoco es avanzado que digamos, en realidad es muy sencillo, nunca lo había comentado.
Es muy habitual tener un Pod y un Service que trabajen juntos. Y en vez de tener dos archivos podemos agruparlos en uno solo. Lo único que tenemos que hacer es separarlos con tres guiones seguidos (---). Podemos añadir tantos objetos como queramos e ir separándolos, se crearán todos al mismo tiempo.
Vamos a verlo con un ejemplo.
apiVersion: v1
kind: Service
metadata:
name: nuestro-servicio-para-nginx-cip
spec:
selector:
proyecto: ejemplo3
utilidad: web
ports:
- protocol: TCP
port: 80
targetPort: 80
name: http
---
apiVersion: v1
kind: Pod
metadata:
name: ejemplo
spec:
containers:
- name: web
image: nginx
ports:
- containerPort: 80
