
Básicamente Kubernetes es un controlador de contenedores.
Tiene muchos beneficios. Los más destacables son:
- Auto escalable
- Desarrollo en varios nodos simultáneamente (rolling deployment).
- Los recursos son vistos como objetos
- Administración de almacenamiento
- Permite plugins gratuitos
Se suele usar para operaciones de alto nivel. Las más comunes son:
- Despliegue de contenedores para aplicaciones (deployment)
- Almacenamiento no volátil de estas (persistent storage)
- Monitoreo de los contenedores (health)
- Gestión de todos los recursos
- Escalado de las aplicaciones
- Alta disponibilidad (HA)
- Redes y carga balanceada
- Corrección de las versiones de las aplicaciones en contenedores (roll out / roll over / roll back)
Partes de Kubernetes
Puede estar formado por tantos ordenadores como queramos añadir. Se divide en:
- Master: El controlador de las actividades
- Nodo: Donde se corren los contenedores
Cada uno tiene sus propias características. Vamos a verlas en detalle.
Nodo Master
Aunque el nodo maestro (master) tenga todo lo necesario para ejecutar sus propios contenedores, no es recomendado usarlo en producción. Lo mejor es que solo se encarguen de la gestión de los nodos trabajadores (workers).
- Kube API server: Utilizada en los nodos trabajadores y clientes para comunicarse de forma segura.
- Kube scheduler: Decide la gestión de las tareas, como por ejemplo, en que nodo se ejecuta cada contenedor.
- Kube controler: Ejecuta controladores. Cada controlador es un deamon (proceso en segundo plano) que está revisando que todo se cumpla. Por ejemplo, que haya siempre un número de réplicas.
- Etcd: Base de datos de claves. Importante tener copias de seguridad.
Nodo Worker:
Es donde están y se ejecutan los contenedores y pods.
- Kubelet: Es el agent, el programa que se encarga de que todos los contenedores y pods estén en correcto funcionamiento.
- Docker –> Pods –> API
- Kube proxy: Define la red general. Se encarga de gestionar las IPs virtuales. Es el encargado de exponer los puertos de cada pod también.
El Docker se encuentra dentro de los Pods y se comunican mediante la API.
Tipos de objetos que podemos crear
Todo en Kubernetes es un Objeto. A la hora de crear un objeto, la forma más habitual es utilizar un archivo YAML y especificar los atributos del objeto. Como mínimo va a necesitar:
- apiVersion
- kind
- metadata
Pero vamos a ir viendo primero la teoría de cada objeto y luego como crear correctamente cada uno.
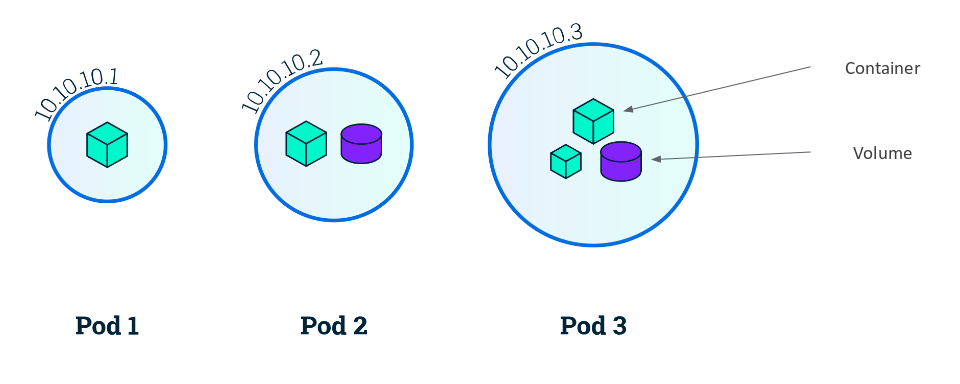
¿Qué es un Pod?
Un pod es un grupo de contenedores. Estos contenedores comparten los volúmenes del sistema y también los nombres de dominio. Es un concepto un poco complicado. Para hacer una metáfora sería como una capa opaca. Interactúas directamente con el pod y él se encarga de los contenedores que los trata como instancias, en ningún momento ves los contenedores.
Los pods son efímeros. Se crean y se destruyen rápidamente. Por eso hay que pensar en el almacenamiento fijo no volátil y en su replicación (ReplicaSet ó Deployment) que vamos a ver a continuación. Son efímeros ya que si un pod se cae por cualquier razón, Kubernetes simplemente va a crear otro nuevo.
En Kubernetes todo es un Objeto y un Pod es el objeto más pequeño que podemos crear.
Recomendaciones para la arquitectura de pods
Nuestra aplicación tiene que estar planeada antes de empezar con la creación de pods. Se suele basar en la norma de 1 proceso para 1 contenedor.
Pero, ¿cuándo elegir la aplicación en 1 pod o ponerla en varios?.
- Si lo tengo todo en el mismo pod es por qué los servicios crecen juntos. Si uno sube, el otro también. Ejemplo: Apache HTTPD (Un servidor Web) y MPM_Netware (Un plugin, módulo de procesamiento, para Apache)
- Si lo pongo separado es por qué puedo tener un pico en una parte y no necesito que la otra consuma más recursos. Ejemplo: MariaDB (una base de datos) y WordPress (Un gestor de contenido).
¿Qué es una etiqueta (label)?
El orden es básico. Al empezar es normal que no las utilices por qué tienes pocos objetos (por ejemplo pods o incluso nodos). Pero una vez tengas mayor cantidad vamos a utilizar las etiquetas para tener cientos ordenados y no perdamos el tiempo.
Se especifica en la creación del objeto, en el archivo YAML. Metadata –> Label. También la puedes añadir con kubectl después de crear el objeto.
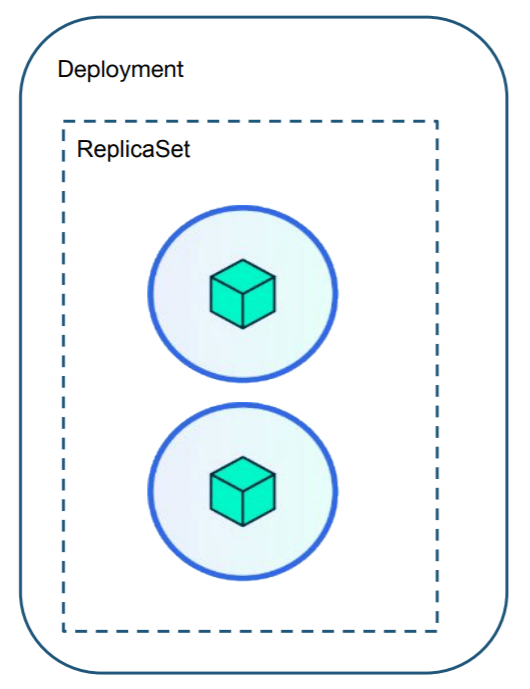
¿Qué es un ReplicaSet?
Se encarga de las réplicas de los pods. Es el utilizado para que no haya caídas. En el momento que detecta que falta uno, crea otro al instante. Por eso cuando se dice que en Kubernetes no hay caídas, el encargado de ello es el objeto ReplicaSet.

Imagen 1: ReplicaSet con 2 Pods “sanos” (activos).
Imagen 2: El ReplicaSet detecta la caída de uno y automáticamente crea uno nuevo.
Se crea especificando el tipo en el archivo de configuración, al igual que un Pod.
¿Cómo sabe qué nodos son los que replicar?
Su funcionamiento es mucho más simple de lo que se podría pensar. Solo tienes que crearlo como objeto ReplicaSet y especificarle las etiquetas de los pods que quieres que replique.
Por ejemplo, si le especificas (Selector –> matchLabels) que los pods con la etiqueta AppApache se repliquen 3 veces, todos los pods con esa etiqueta van a tener 3 réplicas. Da igual que no sean Apache, si tienen la etiqueta se van a replicar.
Son escalables y les puedes especificar una plantilla (template).
¿Qué es un Deployment?
Es el siguiente nivel, por encima del ReplicaSet y por encima de los Pods. Con él puede controlar todos los apartados del ReplicaSet/Pods. Con él, además, podemos escalar los pods por tipos, limpieza y hacer la vuelta a antiguas de versiones (RollBack).
Puedes crear Deployment para crear nuevos ReplicaSet o crear un nuevo Deployment que coja todos los recursos de un Deployment antiguo.
Se crea como un objeto pero especificando el tipo Deployment. Se puede crear tanto con el archivo YAML como con kubectl.
¿Qué es un NameSpace?
El espacio de nombres o NameSpace lo que te permite es aislar objetos. Solo los objetos dentro del mismo espacio de nombres van a verse entre sí.
El namespace por defecto se llama default. También hay otros que son kube-system y kube-public. Y podemos crear tantos como queramos.
¿Qué es un Service?
Lo utilizamos para conectar entre Pods. Es una capa de abstracción que nos permite enrutar mediante las etiquetas (labels) cualquier puerto. Utiliza kube-proxy con IPtables, pero no necesitamos configurarlo aunque se puede. Hay diferentes tipos:
- ClusterIP: Por defecto. Permite la comunicación dentro del Pod.
- NodePort: Asigna un puerto a cada nodo.
- LoadBalancer: Solo en distribuidores Cloud.

Que no es Kubernetes
Como podemos ver en la documentación oficial. Kubernetes no es PaaS (Plataforma como servicio). Por ejemplo, PaaS serían Google App Engine o Heroku. Este tipo de empresas crean una capa de abstracción entre el servidor y el cliente. Así, el cliente solo tiene que centrarse en desarrollar la aplicación o proyecto y no en la arquitectura, almacenamiento, servidores o seguridad.
La diferencia entre el modelo PaaS y Kubernetes es la libertad. Por ejemplo, cosas que no puedes hacer en el modelo PaaS:
- Entrar por SSH para hacer cambios o comprobaciones
- Utilizar software personalizado en una instancia
Este modelo es el indicado para cuando no tienes un DevOps y solo necesitas correr aplicaciones simples de Ruby, Python o Node. Por eso lo suelen usar equipos pequeños.
En cambio, Kubernetes, está indicado para un equipo más amplio.
El lema de Kubernetes es: Sí puede correr en un contenedor, puede correr en Kubernetes.
Como nota, no solo existe Kubernetes como organizador de contenedores (container orchestration) sino que hay gran variedad de ellos, como por ejemplo Swarm. También hay más tipos de contenedores (Cri-o, Rocket). Solo que al haber sido un proyecto de Google, Kubernetes, tiene mayor compatibilidad con los principales distribuidores cloud.
Que sí es Kubernetes
Caso típico a la hora de desarrollar un proyecto o software como una aplicación. Una aplicación web necesita 2 balanceadores de carga (load balancer), ya que tenemos el Front-end (interfaz) y el Back-end (procesado).
En el Frontend tenemos varias máquinas virtuales distribuidas con un balanceador de carga hacia el exterior.
En el Backend tenemos varias bases de datos distribuidas con un balanceador de carga interno hacia el Frontend.

¿Por qué se hace uno externo y el otro interno?. Tenemos que pensar en la distribución y la arquitectura. Una base de datos no debe ser pública directamente desde Internet, es un recurso para usar las máquinas, por eso es interno. En cambio, en las máquinas van a tener salida a Internet, por lo tanto, puede estar fuera y tener su propia IP.
Vale. Hasta aquí todo tiene sentido. Pero queremos más ventajas y mayor rapidez. En este modelo es muy manual, configurando cada máquina y la replicación. Además, es más costoso porque los recursos no están optimizados.
Con Kubernetes el modelo es muy similar, solo que le añade todos los beneficios que hemos visto al inicio de esta entrada.
